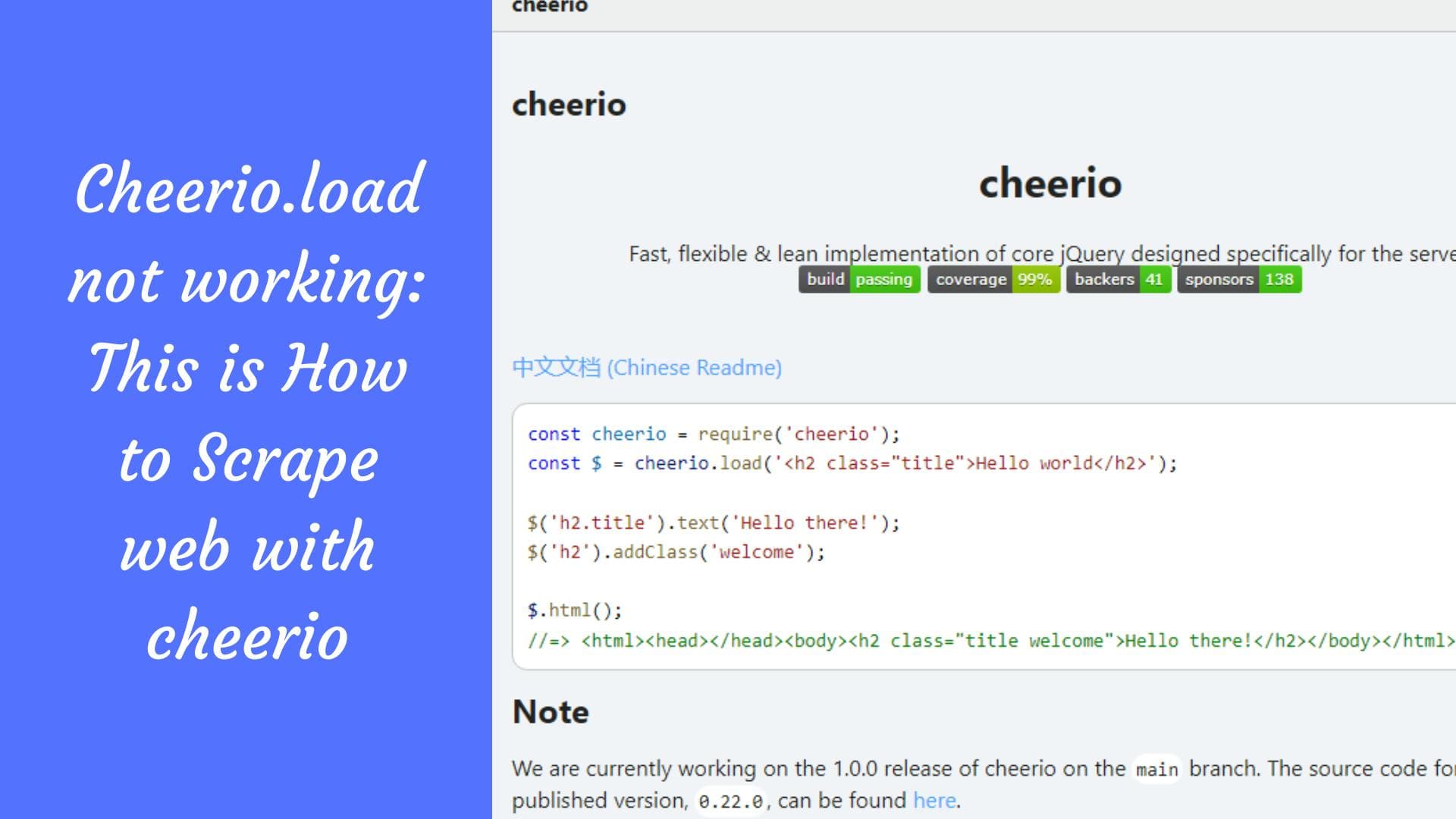
Extrair páginas web no Node com Cheerio: como fazê-lo?
Nesta secção específica, irá compreender como extrair dados de uma página web com a ajuda do Cheerio. Mas antes de optar por este método de extração, precisa de ter autorização para o fazer. Caso contrário, poderá estar a violar a privacidade, a infringir direitos de autor ou os termos de serviço.
Vais aprender a extrair o código ISO 3166-1 alpha-3 para todos os países e várias outras jurisdições. Encontrarás os dados dos países na área de códigos da página ISO 3166-1 alpha-3. Então, vamos começar!
Passo 1: Criar um diretório de trabalho
Aqui, tem de criar um diretório para o projeto executando o comando "mkdir learn-cheerio" na área do terminal. Este comando específico irá criar um diretório, conhecido como "learn-cheerio", e também pode dar-lhe um
Nesta etapa, irá criar um diretório para a sua tarefa executando um comando no terminal. O comando criará um diretório chamado learn-cheerio. Pode dar-lhe um nome diferente, se desejar.
Irá certamente ver uma pasta com o nome "learn-cheerio" criada após executar corretamente os elementos selecionados ou o comando "mkdir learn-cheerio". Depois de o diretório estar criado e de conseguir carregar recursos externos com sucesso, terá de abrir o diretório e um editor de texto para iniciar o projeto.
Passo 2: Inicialização do projeto
Para garantir que o Cheerio seja implementado corretamente neste projeto, tem de navegar até ao diretório do projeto e, em seguida, inicializá-lo. Basta abrir o diretório no editor de texto da sua preferência e, em seguida, inicializá-lo executando o comando "npm init -y". Depois de concluir este processo, pode criar um ficheiro "package.json" no diretório raiz do projeto.
Passo 3 - Instalar as dependências
Nesta secção, irá instalar as dependências do projeto executando o comando "npm install Axios cheerio pretty".
Quando utilizar este comando, o carregamento demorará algum tempo, por isso, seja paciente. Depois de executar o comando com sucesso, pode registar três dependências no ficheiro package.json, logo abaixo da secção de dependências.
A primeira dependência é conhecida como «Axios», a segunda é «Cheerio» e a última é «Pretty». O Axios é um cliente HTTP bem conhecido que funciona no navegador e no Node. Vai precisar dele porque o Cheerio é considerado um analisador de marcação.
Assim, para garantir que o Cheerio consiga analisar a marcação e, em seguida, extrair os dados de que necessita, tem de utilizar
Para garantir que o Cheerio consiga analisar a marcação e, em seguida, extrair os dados de que necessita, deve utilizar o Axios para obter a marcação do site. Pode utilizar um cliente HTTP diferente para buscar a marcação, se desejar. Não tem necessariamente de ser o Axios.
O "Pretty", por outro lado, é um pacote npm para embelezar a marcação, de modo a torná-la totalmente legível quando impressa no terminal.
Passo 4: Analise a página do site que pretende extrair
Antes de extrair os dados da página web, é necessário compreender bem a estrutura de dados HTML resultante da página. Nesta secção
Antes de extrair dados de uma página web, é essencial compreender a estrutura HTML da página de onde irá extrair os dados. Na Wikipédia, aceda ao código ISO 3166-1 alpha-3. Abaixo da secção «código atual», encontrará uma lista de países e os seus códigos.
Agora, basta abrir o DevTools clicando na combinação de teclas «CTRL + SHIFT + I». Caso contrário, pode clicar com o botão direito do rato e selecionar a opção «Inspecionar». Aqui está uma imagem que mostra como a «lista» aparece no DevTools
Passo 5: Escreva o código para extrair os dados
Agora, precisa de escrever o código para extrair os dados. Para começar o trabalho, deve executar o comando «touch app.js» para compilar o ficheiro app.js. Se executar este comando com sucesso, poderá criar o ficheiro app.js dentro do diretório do projeto sem qualquer erro.
Tal como acontece com todos os outros pacotes Node, tem de instalar o pretty, o Cheerio e o anxious antes de começar a utilizá-los. Para tal, tem de adicionar o seguinte código:
const axios = require ["axios"]
const Cheerio = require ["cheerio"]
const pretty = require ["pretty"]
Certifique-se de inserir estes códigos logo no início do ficheiro app.js. Certifique-se de ter um bom conhecimento do Cheerio antes de extrair os dados. Pode analisar a marcação manipulando a estrutura de dados resultante. Isso irá ajudá-lo a aprender sobre a sintaxe do Cheerio e também sobre o processo comum. Aqui está a marcação do elemento UL que contém os elementos LI:
const URL markup = `
<ul class ="fruits">
<li class="frutis__mango"> Manga </li>
<li class="fruits__apple"> Maçã </li>
</ul>
Pode adicionar facilmente este comando de variável específico ao ficheiro app.js.