Resumo: O PHP é uma linguagem perfeitamente adequada para a extração de dados da Web, graças a extensões integradas como o cURL e o DOMDocument, além de um rico ecossistema do Composer que inclui o Guzzle, o Symfony DomCrawler e o Symfony Panther para navegação sem interface gráfica. Este guia orienta-o ao longo de todo o fluxo de trabalho: obtenção de páginas, análise de HTML, armazenamento de resultados em CSV/JSON/MySQL, tratamento de erros e como evitar bloqueios.
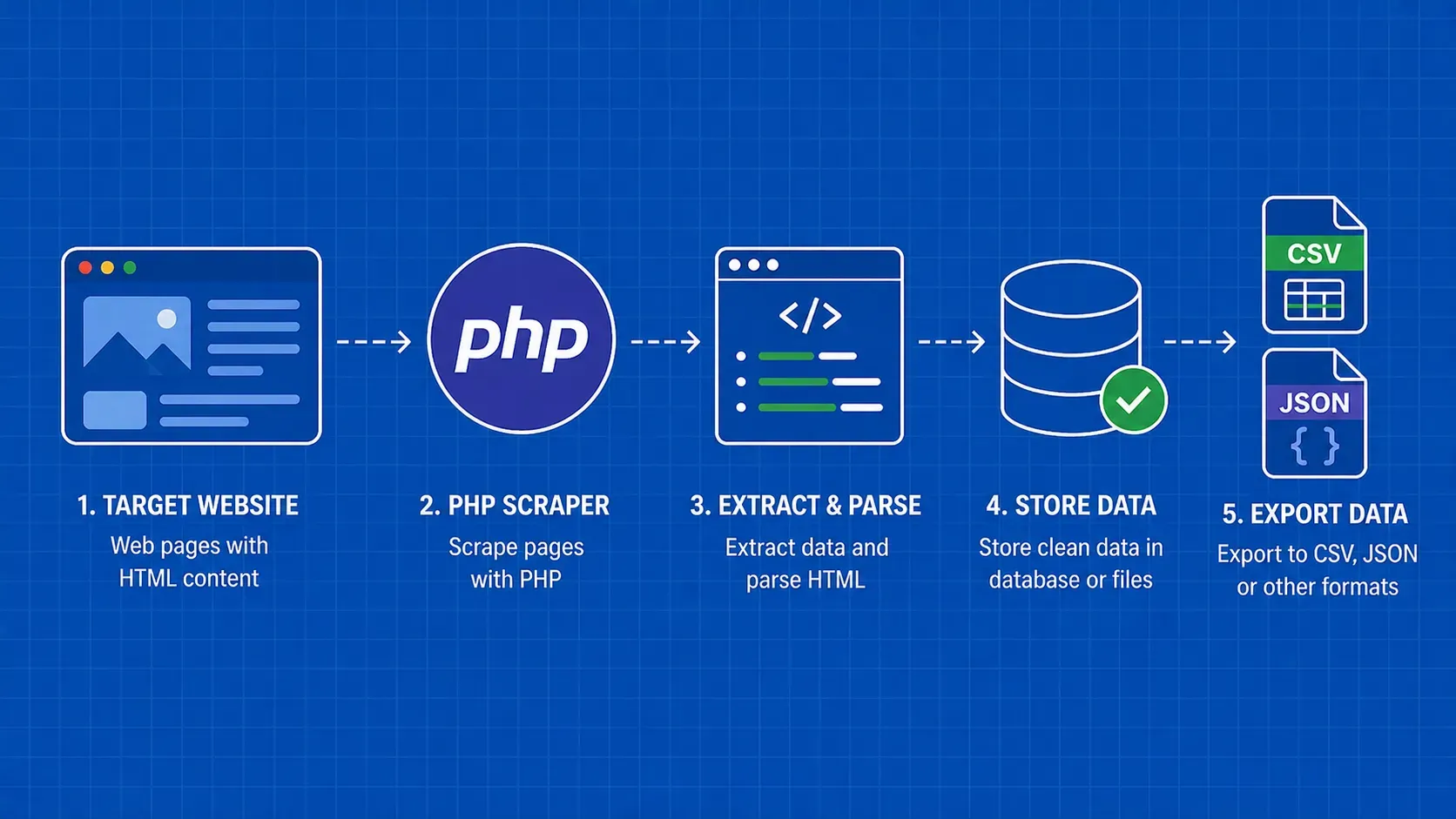
O web scraping com PHP é o processo de obter páginas web programaticamente e extrair dados estruturados do seu HTML utilizando scripts e bibliotecas PHP. Se já escreve PHP no seu trabalho diário, não há razão para mudar de linguagem apenas para extrair dados de sites. O PHP vem com ligações cURL e um analisador DOM integrado de fábrica, e o Composer dá-lhe acesso a clientes HTTP testados em batalha, motores de seleção CSS e até navegadores headless.
Este tutorial destina-se a programadores PHP de nível intermédio que procuram um guia prático e centrado no código. Começará com chamadas cURL de baixo nível, avançará para bibliotecas de nível superior como o Guzzle e o Symfony HttpBrowser, abordará páginas renderizadas em JavaScript com o Symfony Panther e terminará com questões de produção, como armazenamento de dados, tratamento de erros e como evitar listas de bloqueio. Todos os exemplos neste tutorial de web scraping em PHP seguem um único cenário (extrair dados de um site público de listagem de livros), para que possa acompanhar o fluxo de trabalho completo de início a fim, em vez de saltar entre trechos desconexos.



