Web Scraping em Ruby: O Tutorial Definitivo
O que se obtém quando se junta Ruby, um conjunto de gems úteis e algumas horas? A resposta: um scraper web bastante bom. Aqui está um guia passo a passo:
Raluca Penciuc9 min read
Apr 22, 2026Análises aprofundadas sobre a infraestrutura de dados da Web, técnicas de extração e o futuro dos dados estruturados em grande escala.
O que se obtém quando se junta Ruby, um conjunto de gems úteis e algumas horas? A resposta: um scraper web bastante bom. Aqui está um guia passo a passo:
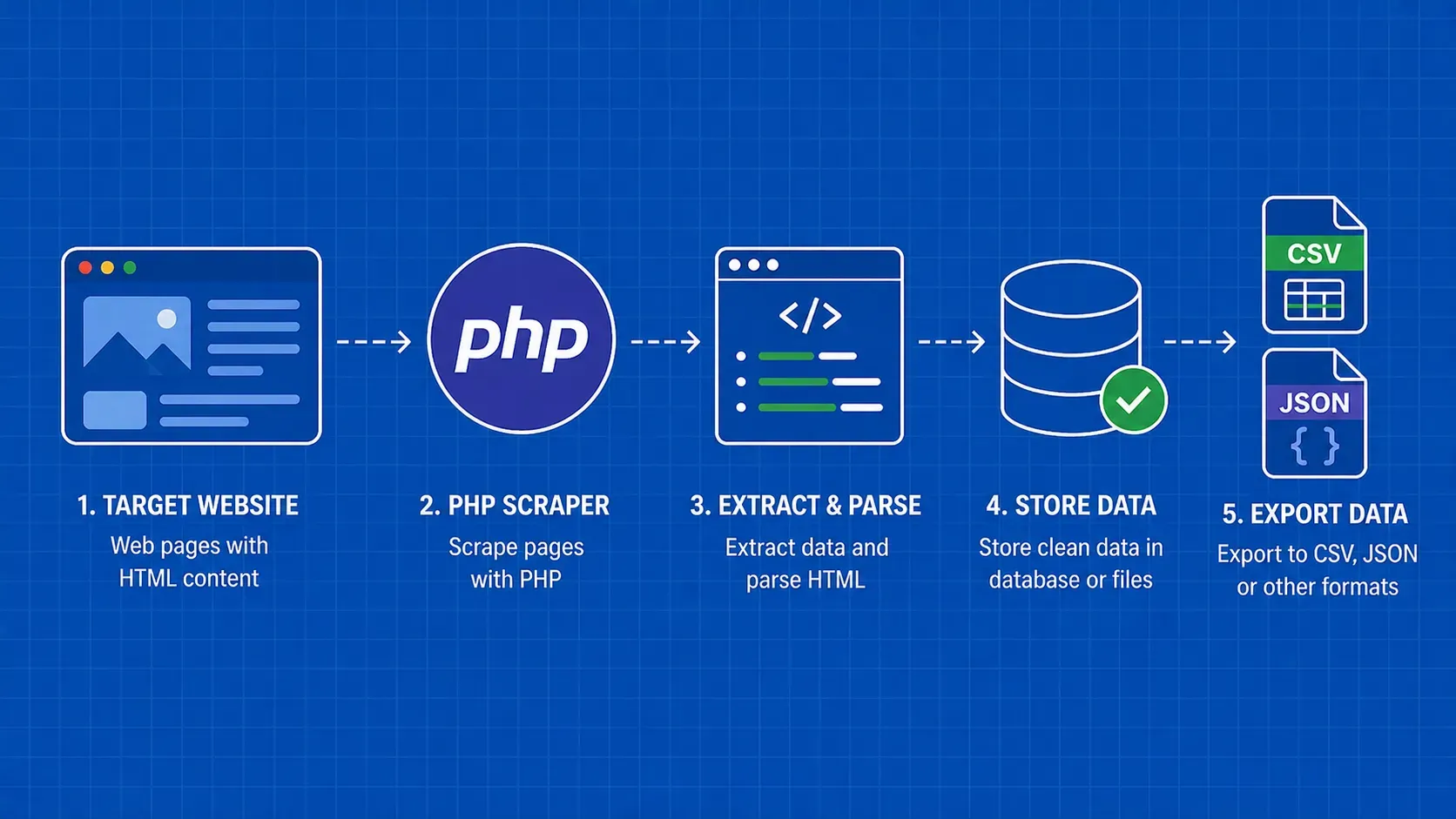
TL;DR: O PHP é uma linguagem perfeitamente capaz de fazer scraping da web, graças às extensões embutidas como cURL e DOMDocument, além de um rico ecossistema Composer que inclui Guzzle, Symfony DomCrawler e Symfony Panther para navegação sem cabeça. Este guia o orienta por todo o fluxo de trabalho: buscar páginas, analisar HTML, armazenar resultados em CSV/JSON/MySQL, tratar erros e evitar bloqueios.
TL;DR: Então, o que são proxies rotativos, em uma linha? Servidores proxy que atribuem um IP diferente a cada solicitação de um pool gerenciado, que é como os scrapers passam pelos limites de taxa por IP, CAPTCHAs e filtros geográficos. Este guia aborda como a rotação funciona, os quatro tipos de pool, o código de configuração em três idiomas e como escolher um provedor.
TL;DR: Esta folha de dicas de XPath cobre a sintaxe, predicados, eixos e funções que você realmente precisa para raspagem da web, além de uma tabela de tradução CSS-para-XPath e exemplos executáveis de Puppeteer e Scrapy. Use-a como referência na próxima vez que um seletor CSS quebrar silenciosamente em um site do qual você depende.
TL;DR: Um web crawler python automatiza o trabalho tedioso de seguir links em um site para descobrir e coletar conteúdo. Este guia orienta-o na construção de um de raiz com pedidos e BeautifulSoup, passando depois para Scrapy para rastreio concorrente, pipelines de itens e exportações de dados estruturados. Você também aprenderá como rastrear de forma responsável, girar proxies para evitar bloqueios e lidar com páginas renderizadas em JavaScript.
Leia este artigo para obter informações úteis sobre listas de proxies, as vantagens das listas de servidores proxy, as melhores ferramentas de API de proxy premium, como escolher uma e muito mais.